
Hibernate Framework
简介:
Hibernate框架是一个全自动的ORM框架,它拥有强大的映射功能,提供了缓存机制、事务管理、拦截器机制、查询语句的多方面支持
本系列笔记可能会遇到的专业词汇有:
Framework, 框架,某一类问题的总体解决方案
ORM,
Object Relationship Mapping, 对象关系映射DATABASE, 数据库,存储数据的一种方式
HQL,
Hibernate Query Language, Hibernate查询语句Transaction, 事务,一组相关的操作
Session, 会话
本系列笔记包含如下的课程内容:
- Hibernate框架原理和开发流程
- 框架缓存机制
- 对象关系映射
- 框架提供的查询机制
- 基于底层的
SQL查询机制 - 基于
HQL查询机制 - 基于
Criteria查询机制
- 基于底层的
Hibernate 缓存机制
![]()
此章节重点讲解 Hibernate框架的缓存机制,含一级缓存、二级缓存、查询缓存
章节重点:
- 一级缓存
- 对象状态管理
- 二级缓存配置和使用
- 查询缓存配置和使用
章节难点:
- 一级缓存管理
- 二级缓存配置
一级缓存
定义:
Hibernate的缓存,是介于物理数据源与应用程序之间,在内存中开辟的一块空间,将数据库中的数据,复制一份临时放在内存中,将来直接从内存读取。
作用:
减少应用程序对物理数据源访问的次数,从而提高了应用程序的运行性能。
机制:
读取数据时,先在缓存中查询。如果在缓存中没有找到需要的数据,则再通过执行SQL语句查询数据库;如果在缓存中找到需要的数据,则就将缓存数据作为结果。
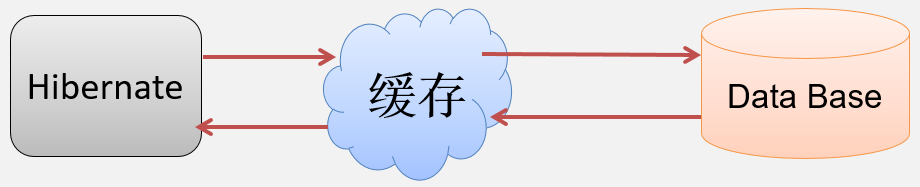
在Hibernate框架中,一级缓存是由Session定义的,同时由Hibernate框架内置实现,它总是开启的。
相比于JDBC,Hibernate的Session相当于JDBC的连接 + Cache,而这个Cache就是一级缓存,它在一般情况下无需开发者进行干预。
如:
1 | ... |
针对一级缓存的操作,主要有两类,一类是查询,一类是增、删、改 操作
R流程
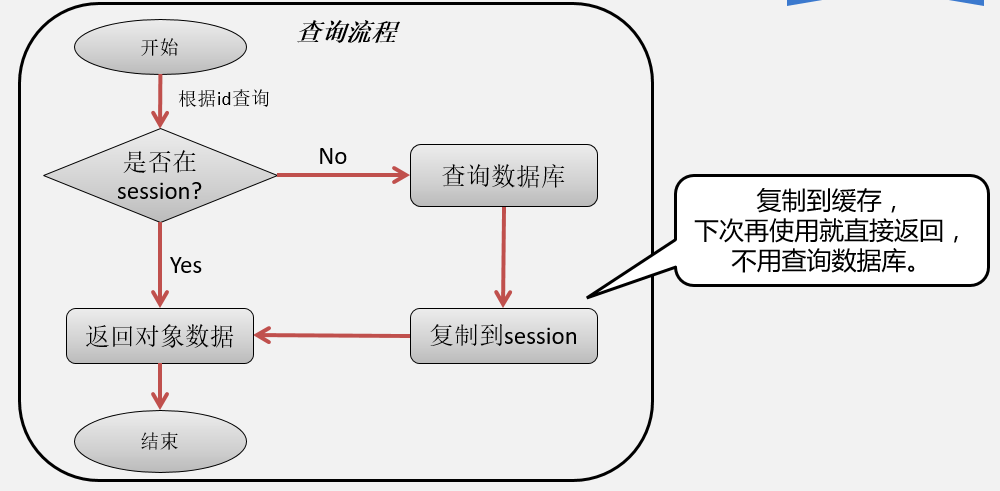
CUD流程
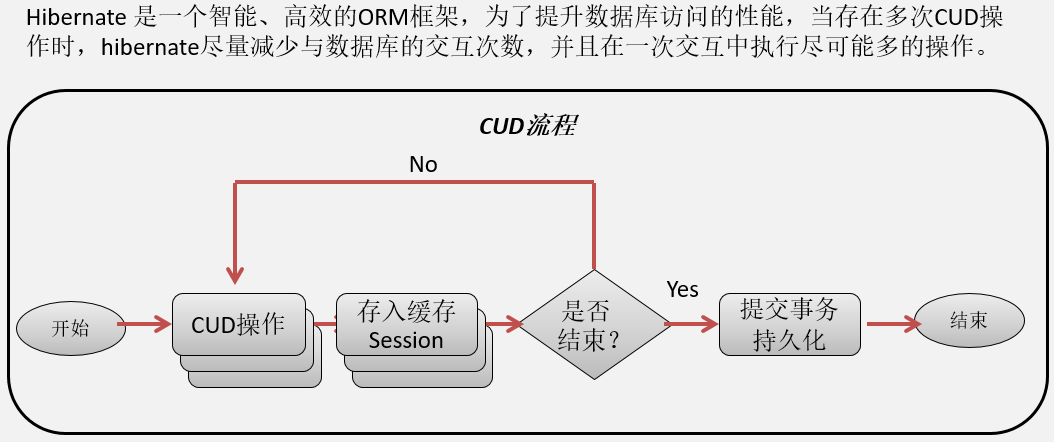
缓存刷新模式(FlushMode)
Session缓存了处于持久态的对象,一旦对象发生改变,这种改变会体现在数据库中,但写入数据库的操作往往会被延后。目的是使用底层JDBC的批量更新来提高性能。
Hibernate更新数据库的时机,是由Session的FlushMode属性决定的,它有如下值:
- FlushMode.AUTO (默认值)
- 在调用Transaction.commit()方法时,更新数据库;或Session持久态属性的改变可能影响即将执行的查询结果之前,更新数据库
- FlushMode.ALWAYS
- 在每一次查询之前,都更新数据库
- FlushMode.COMMIT
- 在调用Transaction的commit()方法时,更新数据库
- FlushMode.MANUAL
- 只有在手动调用session.flush()方法时,才更新数据库
一级缓存示例:
同一个session中,对同样对象类型同样id的对象,仅在第一次查询时,需要执行sql查询语句,之后就直接从缓存中返回,无需产生sql语句.
代码片断:
1 | public void testGet() { |
可以看出,在同一个session中,查询拥有相同类型和id值的对象时,只会执行1次sql,并把第1次查询出来的实例缓存起来,后面再次查询时,首先在一级缓存中查询同类同id值的对象,如果找到,则直接返回.
一级缓存注意事项:
- 一级缓存是Hibernate默认使用的,无需配置即可使用
- 一级缓存是在session上实现的,所以,不能跨session对象来使用
- session的load/get方法支持一级缓存
- 如需要大量的CUD操作,及应时刷新和清空一级缓存,可以调用 flush()和clear()方法
注: get方法和load方法的区别
- get方法当查询的对象id不存在时,会返回null值,而 load方法抛出异常
- get方法在实例本身上面不采用延迟加载策略,在关联多的一边会采用延迟加载。而load方法在实例本身上面就采用延迟加载策略。
对象状态管理
Hibernate框架在一级缓存操作中,把对象分成三种状态,如下:
- 瞬态(Transient), 对象未被持久化,并不在缓存的管理中
- 使用new运算符创建出来,并没有给定与DB表中对应的ID值,处在 瞬态
- 持久态(Persistence), 对象已被持久化,并且也在缓存的管理中
- 内存中有,并且在DB的表中也有与之对应的记录
- 同时,也处在session的管理之中
- 对该对象的改动,在事务提交时都会同步到DB的表中
- 脱管态(Detached),对象已被持久化,但不处在缓存的管理之中
- 内存中有,并且在DB的表中也有与之对应的记录
- 但不处在session的管理之中
- 对该对象的改动,在事务提交时不会同步到DB中
理解和掌握三种状态的对象,可以帮助我们在Hibernate程序中快速理解异常和解决问题
三种状态是可以进行转换的,如下: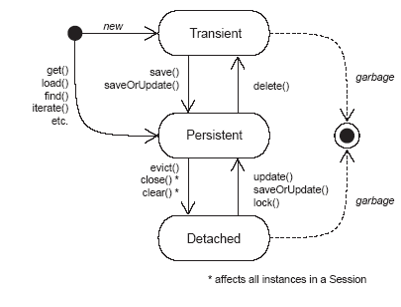
如何区别这三种状态,可以从如下的图标来看:
| 状态 | 内存 | 缓存 | 数据库 |
|---|---|---|---|
| 瞬态(Transient) | YES | NO | NO |
| 持久态(Persistence) | YES | YES | YES |
| 游离态(Detached) | YES | NO | NO |
来看一段代码
1 | public void demo() { |
二级缓存
由于多线程下,每个请求都是一个线程,而每个线程都会创建session。当请求并发时,可能存在的多个session缓存同一个对象的情况,造成内存浪费。为了解决这个问题,Hibernate设计一个比session“更大的总缓存”,即二级缓存。
二级缓存可以被所有的session共享,二级缓存的生命周期和SessionFactory的生命周期一致。
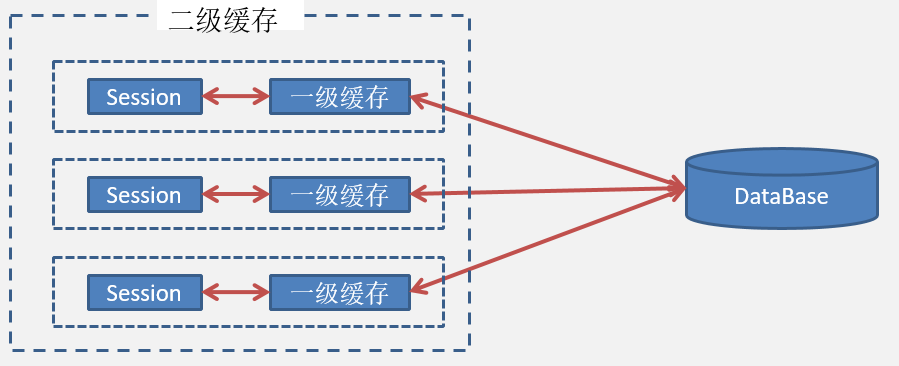
在默认情况下,Hibernate框架并没有开启二级缓存,如若需要,请按如下步骤操作
- 步骤一, 在 hibernate.cfg.xml 文件中启用二级缓存,如下:
1 | <!-- 二级缓存默认是关闭的,需要手动进行开启 --> |
- 步骤二, 在src根目录下配置ehcache.xml文件【从hibernate压缩包/project/etc/文件夹下COPY即可】,此文件内容如下:
1 | <ehcache> |
- 步骤三,在实体类中使用注解,指定哪些实体类的实例需要被放入到二级缓存中。
1 |
|
示例: 两个session都可以共享一级缓存中的对象实例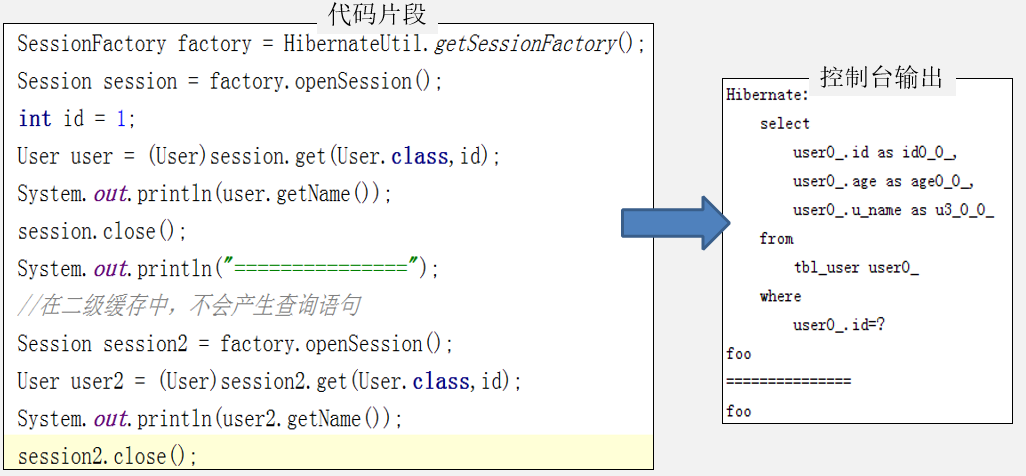
二级缓存注意事项
- 二级缓存需要配置才可使用
- 二级缓存是SessionFactory级的缓存,可以被多个 session 共享
- 二级缓存中适合放入的数据: 经常被使用,但不太更新,数据量较少 情况
查询缓存
查询缓存,也叫三级缓存,由于一级缓存和二级缓存都是以对象为key进行缓存,而查询缓存则是以查询和参数为条件进行缓存的,这为HQL和QBC查询提供了缓存的能力,但是,默认情况下,查询缓存也是关闭的。
出于以下原因,查询缓存默认是禁用的:
一旦查询缓存已保存某些实体类的实例,Hibernate就需保持追踪这些实体类,查看是否会在未来的某个时间点,由于其他事务对这些数据进行了更新,而造成缓存中数据的无效。
要开启查询缓存,需满足以下的条件:
- 二级缓存已经开启
- 程序中存在一些频繁运行的查询语句
- 查询条件不太变化
代码步骤:
- 步骤一:开启二级缓存,配置请查看之前的配置
- 步骤二:在hibernate.cfg.xml 中开启查询缓存
1 | <!-- 配置查询缓存 --> |
- 步骤三:在代码中调用 setCacheable(true)方法,将需要缓存的查询结果加入查询缓存
1 | //代码片断 |
案例, 同一条查询语句同样的条件,查询多次,只输出1条sql语句。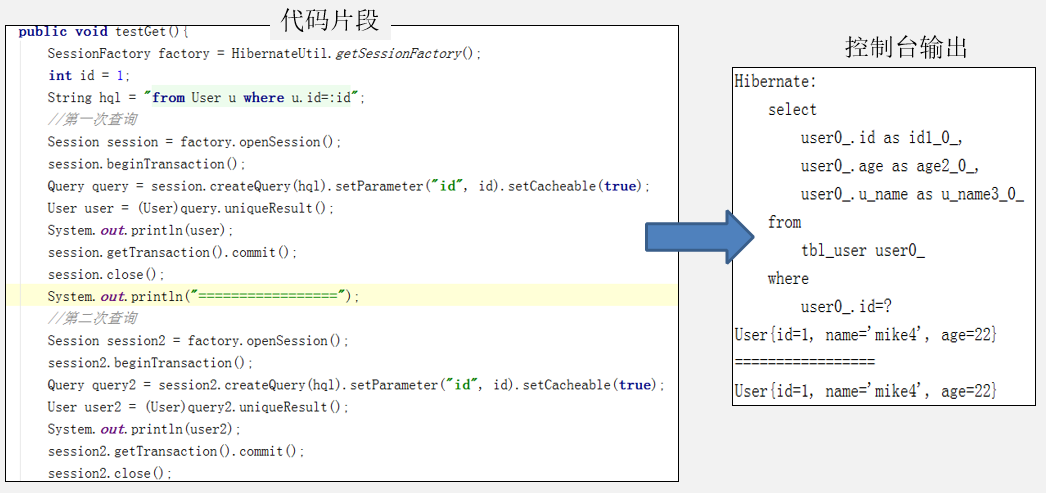
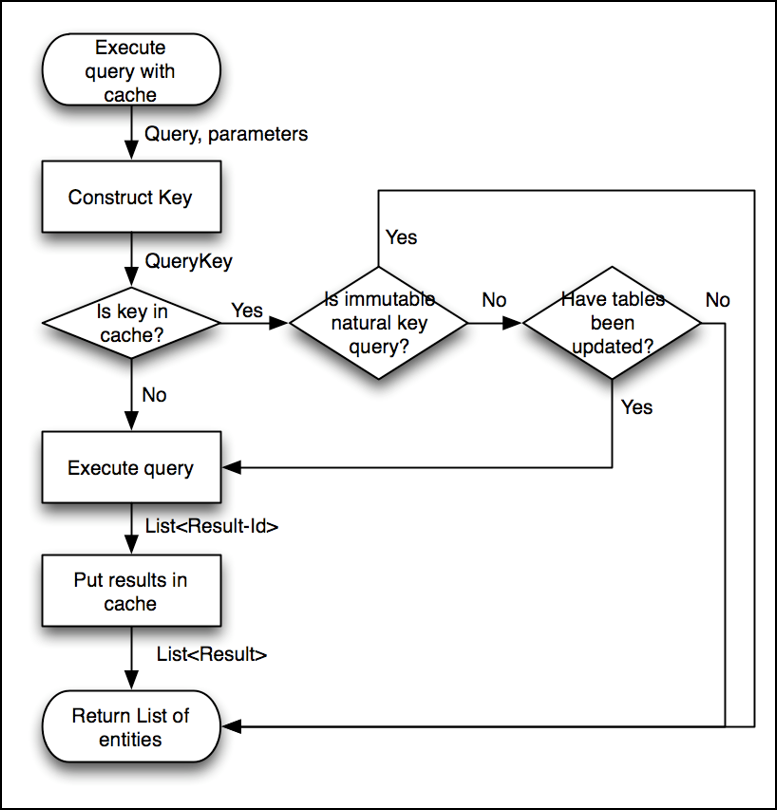
查询缓存的流程
本章小结
- 需要熟悉Hibernate框架的三种缓存的区别
- 掌握Hibernate框架缓存对象的三个状态的特征