
MongoDB
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
主要特点
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=”Sameer”,Address=”8 Gandhi Road”)来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单。
Windows下安装MongoDB
- 官网下载安装文件 www.mongodb.com
- 双击安装
配置 MongoDB
在MongoDB的安装目录下,有 一个 mongod.cfg 的配置文件, 这个配置文件采用 YAML 语法格式。如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
> storage:
> dbPath: D:\database\MongoDB\Server\4.2\data
> journal:
> enabled: true
> # engine:
> # mmapv1:
> # wiredTiger:
>
> # where to write logging data.
> systemLog:
> destination: file
> logAppend: true
> path: D:\database\MongoDB\Server\4.2\log\mongod.log
>
> # network interfaces
> net:
> port: 27017
> bindIp: 127.0.0.1
>
>
其中,我们在启动 mongodb服务之前,需要自己指定 dbpath 和 systemlog 的值,一般是自己创建一个新的数据目录和日志目录【不建议直接使用系统自带的】
- 新建一个 data 文件夹,用来做为 storage的 dbpath
- 在这个data文件夹下面新建 db 和 log 子文件夹
- db 文件夹, 存放数据
- log 文件夹 ,存放系统日志
启动MongoDB服务
打开命令行,执行:
2
>
>
MongoDB以WINDOWS服务方式启动
1 | -- 安装服务 |
使用MongoDB shell客户端
连接到MongoDB
语法:
2
>
MongoDB 和 mysql 中的数据库相关概念对比
| MongoDB | MYSQL | 区别 |
|---|---|---|
| database | database | 一样 |
| 集合 collection | 表 table | 都是数据集 |
| 文档 document | 行 row | 文档是bson格式,行 是逻辑概念 |
| 属性 field或者 键 key | 列 column |
MongoDB的基本操作
创建、删除、查看、使用数据库
1 | -- 查看 |
创建、删除、查看集合【集合相当于 表】
1 | -- 查看集合 |
插入文档【文档相当于行记录】
使用 db.collection_name.insert(doc) 或 db.collection_name.save(doc)
1 | db.emp.insert({ |
更新文档
使用 db.collection_name.update(
, , options) 其中,query 表示更新的条件
update 表示更新的列值
options 主要有:
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
更新指定列: 前面加上 $set:
删除文档
使用 db.collection_name.remove(
, options) 其中,
query 表示删除的条件,满足此条件的记录删除
options 主要有:
- justOne: true|false 如果设置成true或1,表示只删除1行,不设置的话,则删除所有匹配的行
- writeConcern :可选,抛出异常的级别。
查询文档
语法:
2
3
4
5
6
7
8
9
10
11
> 其中,
> {query} 是指查询的条件,语法如下:
> {<field1>: {expression1}, <field2>: {expression2}, ... , <fieldN>: {expressionN}}
>
> 在expression中,可以使用各种运算符,语法: 运算符: value, 如:$gt 表示大于
>
> {projection} 是指投影查询的列,语法如下:
> {field1:true|false, field2:true|flase, ... , fileldN:true|false}
> 也可以使用整数,其中,0代表false, 非0代表true
>
>
指定查询条件的逻辑符号,主要有:
$or
$and 默认值
$nor 异或
$in
$nin
$not
语法:
2
3
4
5
6
7
8
> $or: [
> {条件1},
> {条件2}
> ]
>
> })
>
>
$type运算
根据文档值的类型进行过滤,这个类型要查询官方的手册
limit()和skip() 操作
limit(n) 表示限定多少行
skip(n) 表示跳过多行少
练习:
查询出工资范围在 10000 至 15000之间的员工
1
2
3
4SQL:
select * from emp where salary > 10000 and salary < 15000;
-- MongoDB:
db.emp.find({salary: {$gt: 10000, $lt: 15000}},{_id:0,tag:0})
查询出职位含有 ‘java’ 的员工
1
2
3
4SQL:
select * from emp where title like '%java%';
-- MongoDB:
db.emp.find({title: /java/i})注: 以 i 结尾表示 忽略大小写
查询出名字中以’袁’开头或者工资大于15000或者年龄大于 28岁的员工
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16db.emp.find(
-- 条件 condition
{
$or:
[
{name: /^袁/},
{salary: {$gt: 15000}},
{age: {$gt: 28}}
]
},
-- 投影 projection
{
_id:0,
tag:0
}
)
查询出总记录数
1
2
3
4
5
6SQL:
select count(*) "total" from emp;
-- MongoDB:
db.emp.aggregate([{$group: {_id: null, total: {$sum: 1}}}])
-- 或者
db.emp.find().count(true);以上的语句相当于执行了: select count(*) from emp;
查询出各职称的工资总和。
1
2
3
4SQL:
select title, sum(salary) "totalSalary" from emp group by title;
-- MongoDB:
db.emp.aggregate([{$group: {_id: '$title', totalSalary: {$sum: '$salary'}}}])
基本查询汇总
语法:
db.collection_name.find(
{where}, – 指定查询的条件
{projection} – 指定查询的列
).sort({属性名: 1|-1})
排重的语法:
db.collection_name.distinct(“属性名”,{where})
1.行记录过滤
支持的条件指令
- $gt, $lt, $gte, $lte, $ne
- $in(list)
- …
– 年龄在22至28岁之间员工
1 | db.emp.find({age: {$gte: 22, $lte: 28}},{_id: 0, tag: 0}) |
…
2.模糊匹配
采用正则表达式的方式进行匹配。
…
3.排重
排重的语法:
db.collection_name.distinct(“属性名”,{where})
1 | -- 查询出所有员工的入职时间 |
4.投影查询
可以从两个角度来定义
不想显示哪些域
{属性名: 0} 或 {属性名: false}
只想显示哪些域
{属性名: 1} 或 {属性名: true}
如:
1 | -- SQL |
5.多个逻辑条件
当有多个条件时,要么是 $and, 要么是 $or, 它们的值都是 数组类型。
语法:
db.collection_name.find(
{$or|$and: [
{条件1},
{条件2},
….
{条件N}
]},
{属性名: 0} 或 {属性名: false}
)
1 | -- 工资大于20000并且年龄大于30岁 或者 职位中以是Java开头的 员工 |
6.排序
在查询的方法后面,再调用 sort 方法即可,语法:
sort({属性名: 1 | -1, 属性名: 1|-1, […]})
1代表 升序, -1 代表降序。
如:
1 | -- 按年龄排序显示所有的员工名、职位、工资、年龄 |
7.分页
limit(n) , 只查询出指定的条目数【行数】
skip(n), 跳过指定的条目数【行数】
所以,分页的查询是基于以上两个函数,其中, limit的参数代表 每页多少行[pageSize], skip的参数应该是 (当前页 - 1) * pageSize.
如:
1 | db.emp.find({},{name:1,salary:1, age:1, title:1, _id:0}).limit(5).skip(5) |
8.统计行数
调用 count() 方法
1 | -- 查询有多少员工的工资大于15000元 |
聚合操作
db.collection_name.aggregate([管道操作])
常用的管道操作符:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
语法规则:
1 | db.collection_name.aggregate([ |
其中,_id 后面指定分组的列,可以有多列
$group 之前的 $match 表示 where 子句
$group 之后的 $match 表示 having 子句
$sort 表示排序
$unwind 表示将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
如:
1 | -- 查询出员工总记录数 |
注:
aggregate 函数的执行过程也叫上管道操作,前面的执行结果做为后面的执行输入。
管道操作的图示
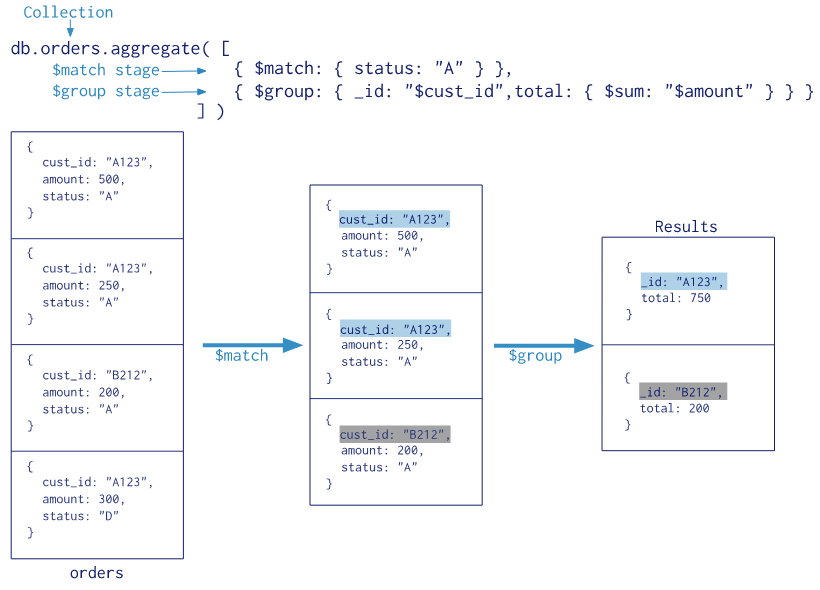
1 | -- MongoDB: |
索引操作
作用:
- 提高文档的检索效率
- 索引是存储在内存之中的,索引的效率非常高。
创建索引
db.collection_name.createIndex({field: 1 | 0, fileld: 1|0, … }, options)
或
db.getCollection(“collection_name”).createIndex({field: 1 | 0, fileld: 1|0, … }, options)
其中,1代表 升序索引, 0 代表降序索引
查看索引
db.collection_name.getIndexes()
– 查看索引大小
db.collection_name.totalIndexSize()
删除集合所有索引
db.collection_name.dropIndexes()
或
db.collection_name.dropIndex(index_name)
MongoDB 客户端
可以使用 ROBO Studio 3T, 下载地址: https://studio3t.com/