
雪花算法
SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,基本上保持自增的。本文主要是是实现了单机版本的算法,使用多台计算机构成分布式的ID生成服务也是可以的,预留了相关的方法参数。
应用范围
在jdk中自带的uuid算法可以来生成唯一性的32位字符串【拼接上‘-’之后,是36位,如:’4211210a-ba56-41b4-b055-6262411970a4’】,uuid算法得到的id是无序的,而且是字符串,数据表记录多时,查询效率不高
基于数据库的sequence【通过表也可以模拟sequence】来生成,在分布式系统中更新记录不方便,只能操作主表的更新。
雪花算法在分布式系统中可以较好地使用
原理
把64位进行拆分,分为如下几个部份
- 第1部份只占1位,而且必需为0,因为最高位0表示正数。
- 第2部份是时间戳,占41位【为什么是41位,后面会介绍】,最多可以表示2^41,大约是69年
- 第3部份是产生的机器号,占10位【也可以是其它位数,不一定非得是10位,官方约定是10位】,最多可以表示2^10,相当于1024台机器,这部分可以划成两个维度,如下:
- 3.1 拿5位出来做为机房号,最多可以表示 2^5个机房号,也就是最多32个机房编号
- 3.2 拿5位出来做为机器号,最多可以表示 2^5台电脑,也就是最多32台电脑编号
- 第4部份是时间戳,占12位,相当于在同一个毫秒内,可以最大支持2^12,也就是4096个序号【普通的计算机根本达不到,我的电脑测试下来是远远用不完的】
如下图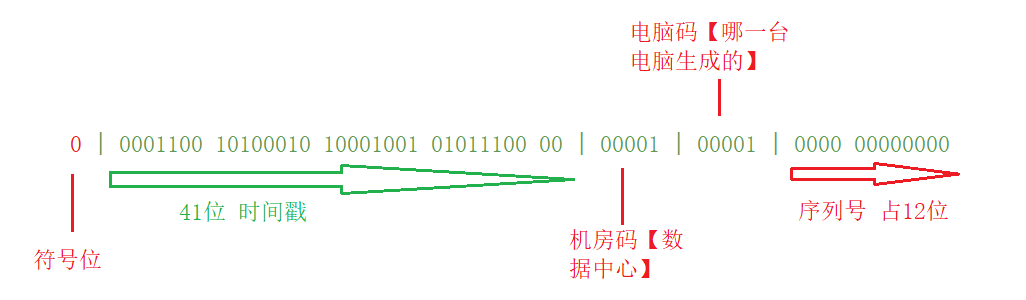
代码实现
1 | public class IdGenerator { |
上面有详细的注释,这里就不再做解释了
测试
1 | public class UseIdGenerator { |
上面循环了10000次,可以看到,生成的ID是在同一个毫秒内是连续的。
附录:时间戳为什么是41位?
我个人理解是目前计算机的系统时间是从1970年1月1号午夜开始到现在经过的毫秒数,刚好使用到了41位,有兴趣的可以自己写如下代码来验证一下
1 | public class XXX { |
这个结果刚好是41,所以,如果时间戳低于41位的话,则就不能精确到毫秒了。
关注
关注微信公众号后留言